Quand on veut augmenter le nombre d’IPC (Instructions par Cycle) d’un processeur on peut soit Accélérer l’accès à la mémoire, soit se débrouiller pour que l’exécution des instructions en elle même soit parallélisée.
L’exécution superscalaire
Quand un processeur va exécuter une instruction il va passer par 6 phases
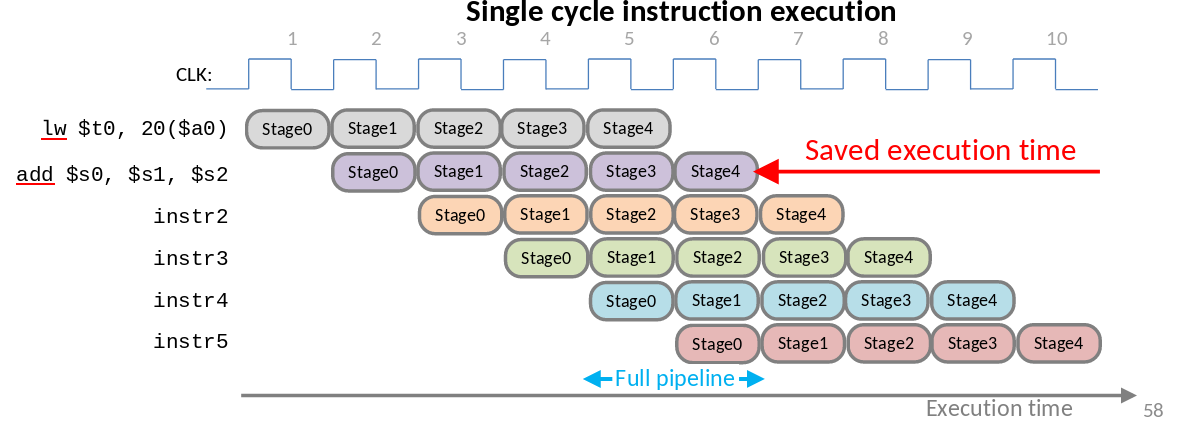
Si on devait poser des instructions exécutées séquentiellement sur une timeline on pourrait se rendre compte que l’on perd temps car chaque phase n’est pas instantanée. Pour ce faire nous pouvons avoir N [[Les processeurs#le-datapath|datapath]] cd qui nous permet de paralléliser les instructions en lançant le prochain cycle d’exécution dès qu’on en démarre un.L’exécution d’instructions
Un processeur ne peut pas exécuter des instructions instantanément, il est séquencé par une horloge (appelé très souvent clock) qui émet périodiquement des cycles, exprimés en GHz. Une instruction s’exécute donc sur plusieurs cycles, 6 grandes phases vont se dérouler pendant ces cycles pour exécuter une instruction:
- Fetch: Récupération de l’instruction depuis la mémoire et stockage de cette dernière dans un registre (l’Instruction Register)
- Decode: Le processeur détermine le code d’opération et détermine donc les arguments qui suivent
- Evaluate Address: Récupère les adresses en mémoire si l’instruction en a besoin
- Fetch Operands: Récupère les opérandes sources depuis la mémoire (par exemple les nombres à additionner)
- Execute: L’ALU reçoit l’instruction et les opérandes puis retourne un résultat
- Storage: Écriture du résultat dans un registre
Lien vers l'originalINFO
À noter que la phase
4. Fetch Operandsse fait en même temps que la phase2. Decodesur les micro-architectures récentes
ATTENTION
Un Processeur superscalaire n’est pas la même chose qu’un processeur multicœur, un multicœur contient plusieurs puces qui peuvent lancer des thread superscalaires
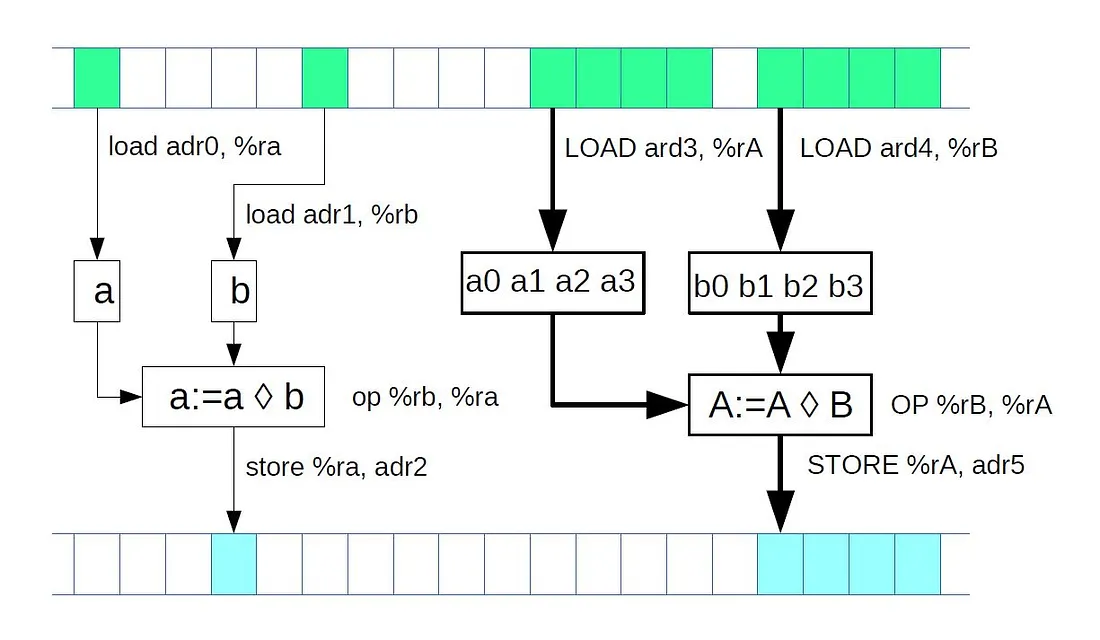
les instruction vectorisées
QUOTE
Vector computations are computations where instead of one operation, multiple operations of the same type are performed on several pieces of data at once when a single processor instruction is executed. This principle is also known as SIMD (Single Instruction, Multiple Data)
- https://videocompressionguru.medium.com/vector-instructions-part-i-343723b103f
Plus d’informations sur la page SIMD