Les cartes graphiques sont des mini-ordinateurs dont les processeur ont des micro-architectures qui permettent l’exécution d’instructions SIMD et donc de la parallélisation.
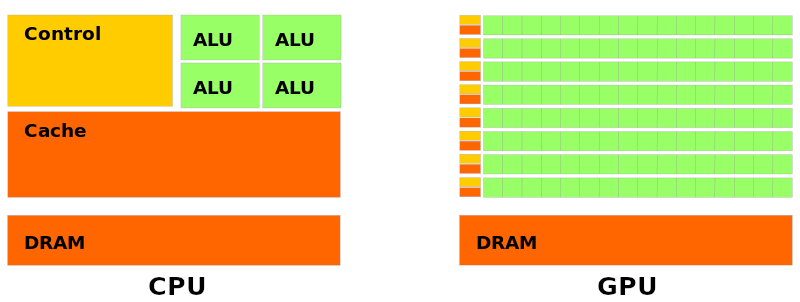
Quand on code un programme pour une carte graphique en CUDA/OpenCL on n’utilise pas d’instructions SIMD mais des thread ayant chacun son propre contexte mais exécute le même code et manipule la même mémoire.
Chaque thread a ses propres registres, sa propre stack et son propre program counter (ou Compteur ordinal: l’adresse vers la prochaine instruction).
| Lexique | Signification |
|---|---|
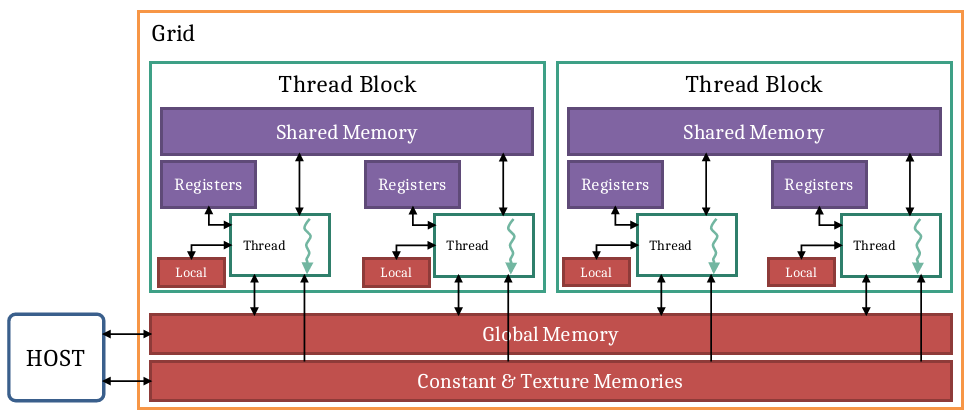
| Warp/Thread block | Groupement de threads, chacun d’entre eux exécuté par une unité fonctionnelle |
| Grid | Groupement de Warps dans lequel un Kernel est invoqué |
| Kernel (GPU Code) | Code d’un thread |
| CPU Code | Code appelant le Kernel sur X thread |
| SM | Streaming MultiProcessors il s’agit d’un processeur qui se voit scheduler un Warp et les envoie dans une Unité d’exécution. |
| Theorical Occupancy | Quantité de Warps pouvant être lancés par l’utilisateur |
| Warps éligibles | Warps actifs pouvant être exécutés |
| Stalled Warps | Warps actifs en attente |
| Warps actifs | Stalled Warps + Warps éligibles |
| Warps sélectionnés | Warps éligibles en cours d’exécution |
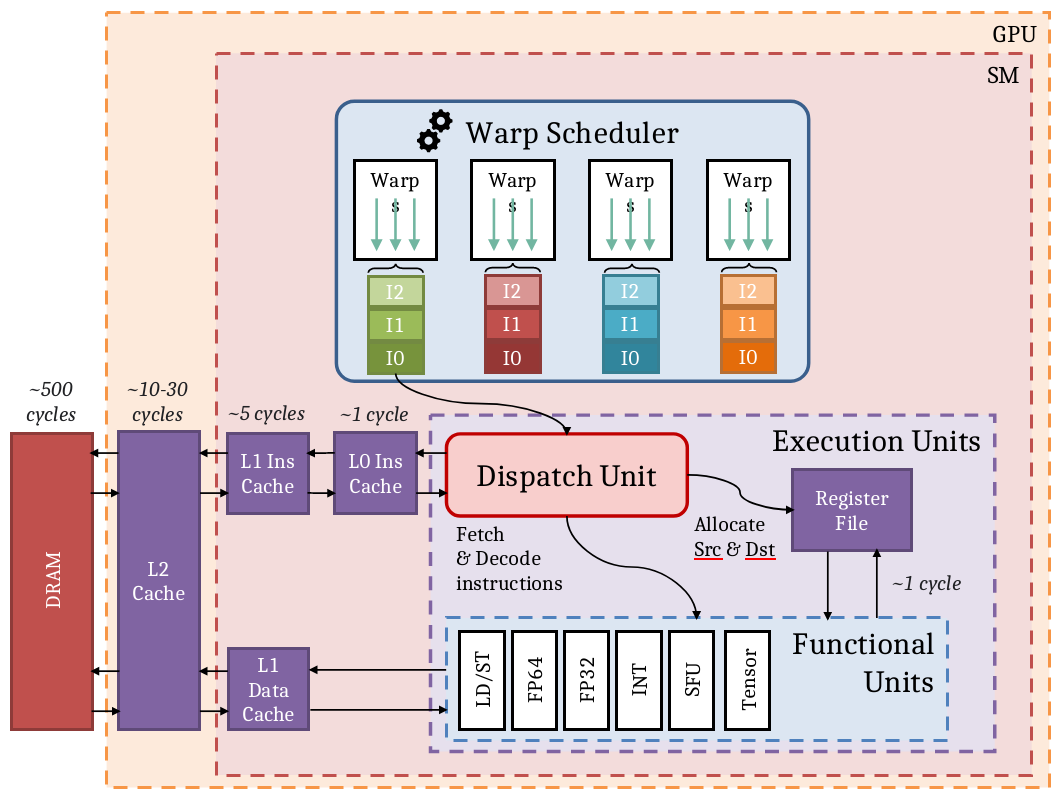
TIP
On peut voir les warps du SM comme des instructions