Fonction coût
Quand on fait un modèle de machine learning on préfère que les erreurs dans les prédictions de nôtre modèle soient les plus petites possible. On utilise donc une fonction coût , utilisant l’approche méthode des moindres carrés qui nous permet de quantifier l’écart entre les prévisions obtenues et les observations que l’on a eu pendant l’entraînement.
Brève explication
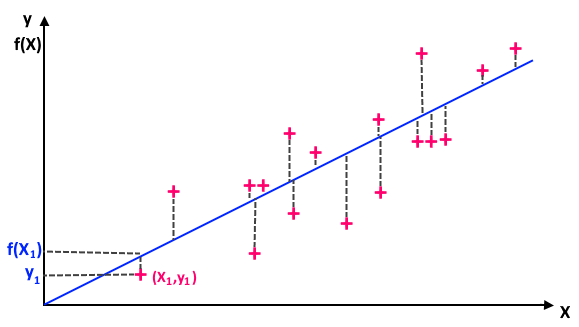
Elle [La fonction coût] permet d’ajuster un nuage de points (observations) représentés sur un plan (diagramme de dispersion) où l’axe des abscisses () représente la variable explicative et où l’axe des ordonnées () représente la variable expliquée. Le centre de gravité de ce nuage est représenté par le point dont les coordonnées sont (moyenne des , moyenne des ). La méthode des moindres carrés consiste à rechercher la relation affine qui lie les variables et ; ce qui revient à définir l’équation de la droite du type , qui passe le plus près possible de tous les points, autrement dit qui [minimise l’écart et donc les erreurs].
Ci-dessous un tracé de
- https://franckybox.com/fonctions-de-cout-et-machine-learning/
TLDR
représente la somme des erreurs au carré du modèle pour toutes les features , le résultat attendu étant et le résultat donné par le modèle
Gradient Descendant
L’algorithme de gradient descendant est un algorithme itératif permettant de trouver les paramètres tel que la fonction coût donne le résultat le plus petit possible. On va chercher à converger vers le minimum de .
L’algorithme marche en dérivant sur un point plusieurs fois et en avançant dans en fonction:
- Si la dérivée de sur aka la step size est faible alors on approche du minimum de , on va donc faire un petit pas.
- Si la step size est importante alors le minimum de (donc du taux d’erreur est importante) est loin, on va donc faire un grand pas.
Sauf que notre saut pourrait être trop grand au point d’avoir une erreur plus importante.
On va donc définir que: Soit un réel positif très petit appelé le learning rate, réduisant le saut.
On arrête l’algorithme quand la dérivée sur est plus petite que le learning rate.
IMPORTANT
Plus est petit plus nos sauts seront précis mais la convergence prendra du temps en échange
Vidéo d'illustration